◎はじめに
韓国語を学習していると、
* 다치다(怪我をする)
* 닥치다(迫る / 黙る)
* 닫히다(閉まる)
のような発音の似た単語に出会うことがあります。
まずは実際の音声を聞いてみてください。
다치다(怪我をする)
닥치다(迫る / 黙る)
닫히다(閉まる)
日本語話者にとっては、いずれも「タチダ」のように聞こえることが多く、聞き分けに苦労する学習者も少なくありません。
しかし、本当にこれらの単語は音響的にも似ているのでしょうか。
以下は、3単語それぞれのスペクトログラムです。
・다치다のスペクトログラム
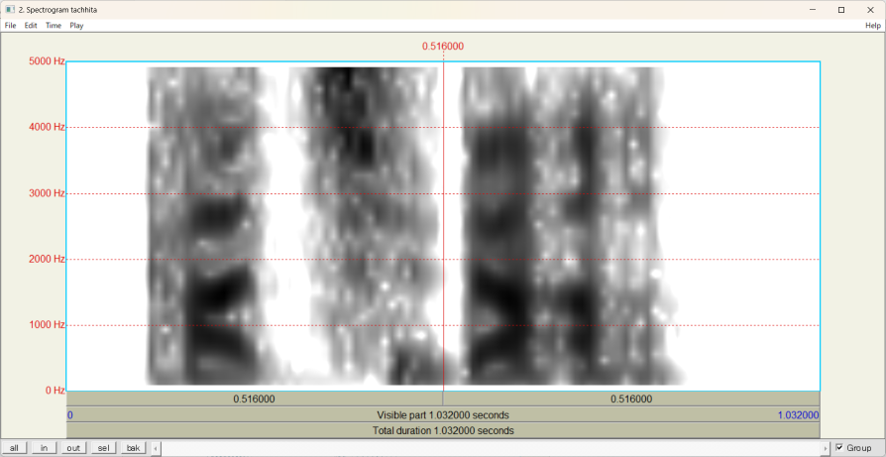
・닥치다のスペクトログラム

・닫히다のスペクトログラム

各単語のスペクトログラムは異なって見えますが、具体的に、どの時点で、どの周波数帯に、どの程度の差があるのかを目視だけで判断することは容易ではありません。
そこで、TTS(音声合成)で生成した韓国語音声を用い、Praatスクリプトを用いてスペクトログラム分析結果をCSVファイルに出力し、各単語の主要周波数帯の時系列推移の差分を解析しました。
- なぜこの3語を選んだのか
今回分析対象としたのは、
* 다치다(ケガする)
* 닥치다(迫る / 黙る)
* 닫히다(閉まる)
の3語です。
これらは日本語話者にとって非常に紛らわしい単語です。
カタカナ表記では、
* ダチダ
* タクチダ
* タチダ
などと書かれることがありますが、実際の発音を聞くと、その違いは必ずしも明瞭ではありません。
特に学習初期では、「今、どの単語を言ったのだろう?」と迷うことも多いでしょう。
そこで、今回は、
* 다치다-닥치다
* 다치다-닫히다
* 닥치다-닫히다
の3ペアについて主要周波数帯の時系列分析を実施しました。
- 分析方法
今回の分析手順は以下のとおりです。
・使用音声TTS(Text-to-Speech)で生成した韓国語音声
・使用ソフト:Praat
・分析手順
1) 各単語の広帯域スペクトログラムを作成
2) スクリプトでCSV出力
3) 0.02秒ごとの強度データを取得
4) 各時間点で単語間の差分を計算
・対象周波数:主として、200Hz、400Hz、600Hz、800Hz、1000Hzの推移を可視化
さらに実際の計算では、200Hz~4800Hzまでの複数周波数帯のデータも利用しました。
これにより、
「どの時点で」
「どの周波数帯に」
違いが現れるのかを調べることができます。
- 差分推移グラフの考察
3-1. 다치다-닥치다
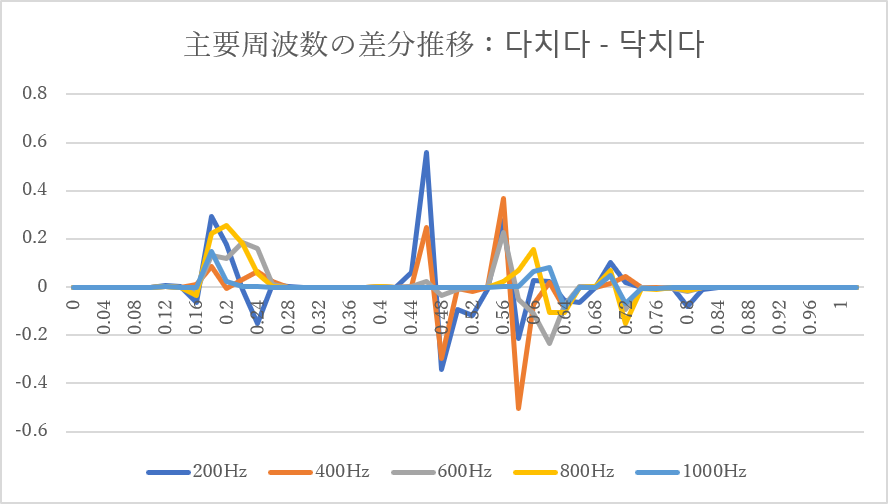
この組み合わせでは、
* 約0.18秒付近
* 約0.46秒付近
* 約0.58秒付近
に比較的大きな差分が現れました。
特に200Hz帯では大きなピークが観察されます。
一方で、それ以外の時間帯では差分は比較的小さく、両単語が音響的に比較的近いことが示唆されます。
3-2. 다치다-닫히다
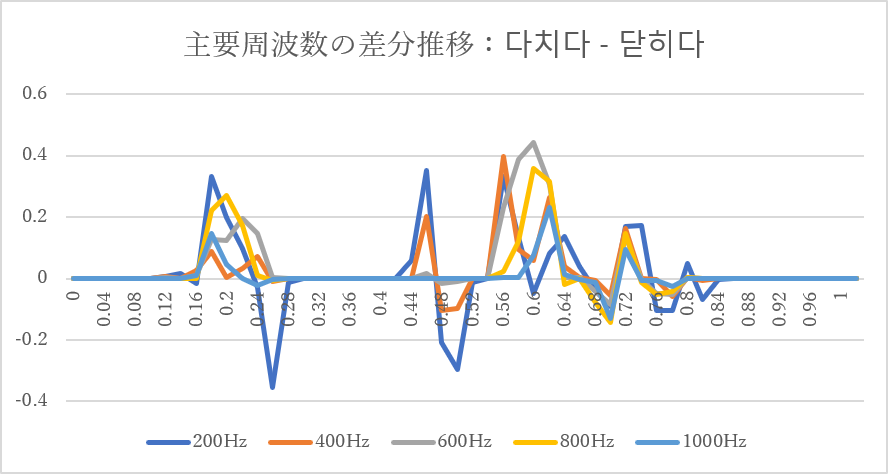
この組み合わせでは、
約0.56~0.66秒付近で大きな差分が集中しました。
特に
* 400Hz
* 600Hz
* 800Hz
の中周波数帯で顕著な差が現れています。
닫히다 に含まれる「ㅎ」の存在が、この差異に関係している可能性があります。
3-3. 닥치다-닫히다

3組の中では最も鋭いピークが見られました。
約0.58~0.66秒付近で、
400Hz帯
600Hz帯
に大きな差分が集中しています。
瞬間的な差分としては今回最大クラスであり、両単語の子音構造の違いが強く反映されていると考えられます。一方、平均絶対差では 다치다-닫히다 が最大であり、局所的な差と全体的な差は必ずしも一致しないことも分かりました。
- 数値比較
本記事では、3単語それぞれのスペクトログラムを記録したCSVデータを用いて、各時間・各周波数帯における差分値から、以下の3つの指標を算出しました。
・平均絶対差(Mean Absolute Difference)
差分の絶対値の平均です。全体としてどの程度似ているかを表します。
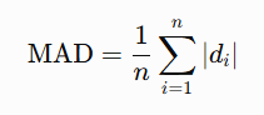
・RMS差分(Root Mean Square Difference)
差分を二乗して平均し、平方根を取った値です。大きな差分をやや重視して評価する指標です。

・最大差分(Maximum Absolute Difference)
差分の絶対値の最大値です。最も違いが大きかった瞬間を表します。
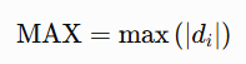
以下、それぞれの指標による3単語間のスペクトログラム差分の比較結果です。
・平均絶対差(Mean Absolute Difference)
|
比較ペア |
平均絶対差 |
|
다치다-닥치다 |
0.00846 |
|
다치다-닫히다 |
0.01089 |
|
닥치다-닫히다 |
0.00929 |
最も差が大きかったのは
다치다-닫히다
でした。
・RMS差分(Root Mean Square Difference)
|
比較ペア |
RMS差分 |
|
다치다-닥치다 |
0.0403 |
|
다치다-닫히다 |
0.0464 |
|
닥치다-닫히다 |
0.0463 |
こちらも
다치다-닫히다
がわずかに最大でした。
・最大差分(Maximum Absolute Difference)
|
比較ペア |
最大差分 |
|
다치다-닥치다 |
0.560 |
|
다치다-닫히다 |
0.443 |
|
닥치다-닫히다 |
0.599 |
瞬間的な差分では
닥치다-닫히다
が最大となりました。
- 考察
今回の分析から、
日本語話者には似て聞こえる
* 다치다
* 닥치다
* 닫히다
であっても、音響的には必ずしも同程度に近いわけではないことが確認されました。
特に、닫히다 を含む比較では一貫して差分量が大きくなる傾向が見られました。
これは 닫히다 に含まれる「ㅎ」の音響的特徴が影響している可能性があります。
また、다치다-닥치다は音韻的には異なる単語であるにもかかわらず、今回の指標では比較的近い結果を示しました。
今回の結果は、「日本語話者には同じように聞こえる」という主観的印象と、「実際の音響的距離」が必ずしも一致しないことを示しています。
韓国語学習では、単にカタカナ表記に頼るのではなく、音響的特徴や子音構造にも注目することが重要なのかもしれません。
■付録:PraatスペクトログラムCSV出力スクリプト
本記事で使用したCSVは、以下のPraatスクリプトにより生成しました。
以下のスクリプトは音声分析の学習・研究目的で公開しています。利用によって生じた結果について筆者は責任を負いません。内容の正確性には努めていますが、環境やPraatのバージョンによって結果が異なる場合があります。
各単語について、Praatから広帯域スペクトログラムの周波数成分をCSV形式で出力しました。CSVサイズと視認性のバランスを考慮し、時間方向0.02秒、周波数方向200Hz間隔でサンプリングしています。
同一時刻・同一周波数帯に対応するセル同士の符号付き差分(前者−後者)をExcelで算出しました。
|
#出力CSV outputFile$ = "C:\YourFolder\spectrum_wide.csv"
# 音声読み込み(WAV推奨) # 分析対象ファイルの名称 Read from file: "C:\YourFolder\sample.wav"
snd = selected("Sound")
selectObject: snd To Spectrogram: 0.005, 5000, 0.01, 100, "Gaussian"
# 分析条件 #・Window length: 0.005秒 #・Maximum frequency: 5000Hz #・Window shape: Gaussian
spec = selected("Spectrogram") selectObject: spec
timeStep = 0.02 freqStep = 200 maxFreq = 4800
# ヘッダー作成 header$ = "time" freq = freqStep while freq <= maxFreq header$ = header$ + "," + string$(freq) + "Hz" freq = freq + freqStep endwhile
writeFileLine: outputFile$, header$
tStart = Get start time tEnd = Get end time
time = tStart while time <= tEnd row$ = string$(time)
freq = freqStep while freq <= maxFreq val = Get power at: time, freq
if val = undefined row$ = row$ + "," else row$ = row$ + "," + string$(val) endif
freq = freq + freqStep endwhile
appendFileLine: outputFile$, row$
time = time + timeStep endwhile
|